

Artificial intelligence (AI), divided into machine learning (ML) and deep learning, is a rapidly changing field. Luckily, developers are in the driver’s seat.
Either way, central to this revolution are open-source large language models (LLMs), which provide flexibility, transparency, and control that no other platform can.
If you’re building smart apps or training your own models, choosing the best open-source LLM can unlock tremendous potential.
Unfortunately, in 2025, there are many open-source LLMs, making it too hard for developers to choose their best fit.
Indeed, speed is an important element when choosing the best open-source LLM, but other models excel in accuracy or flexibility.
Fortunately, we’ve tried, compared, and assembled the definitive top-ten list to make the search easy. Well, now keep reading to find out the best open-source LLM for your next great idea.
Quick Overview of Best Open Source LLMs in 2025
- DeepSeek R1: Best for scientific tasks
- Qwen2.5-72B-Instruct: Best for multilingual performance
- LLaMA 3.3-70B: Best for general-purpose tasks
- Mistral-Large-Instruct-2407: Best for creative content generation
- Phi-4: Best for edge deployment and lightweight coding tasks
- Gemma 2-9B-IT: Best for developers who need faster code generation
- Vicuna-13B v1.5: Best for natural conversations
- BLOOMZ-7B1: Best for global content
Best Open Source LLMs in 2025
1. DeepSeek R1
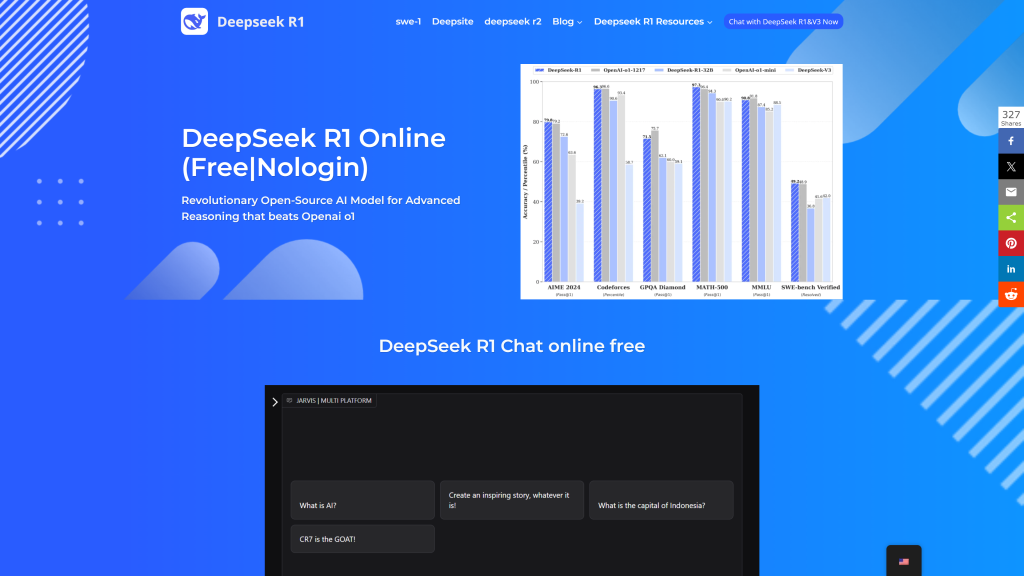
DeepSeek R1 is the best open-source LLM, a large language model ranked as a logic master in digital form.
Interestingly, it can tackle complex tasks with an impressive step-by-step reasoning approach.
Remember that it doesn’t just give answers; rather, it shows its work like a good math student.
When you need clarity in decision-making or explanations that make sense, DeepSeek R1 delivers perfectly.
It easily handles logical problems, dense scientific content, and real-time decisions. That means you can undoubtedly use it to solve math problems or parse long research papers.
One standout feature of DeepSeek R1 is its context window of 128K tokens.
That means you can feed it entire books or extensive documents without losing coherence.
Also, the Mixture of Experts (MoE) architecture activates only what’s necessary, keeping it fast and light.
Key Features
- 128K token context window
- Mixture of Experts (MoE) architecture
- Step-by-step reasoning outputs
- Supports 20+ languages
- Strong scientific and technical knowledge
| Pros | Cons |
| – Excellent logical reasoning and transparency – Efficient resource use with MoE – Versatile across domains and languages | – Not ideal for casual or creative writing – Slightly complex to fine-tune for beginners |
2. Qwen2.5-72B-Instruct
If you run a business, develop learning materials, or need solid multilingual support, Qwen2.5 won’t disappoint.
It balances size and beauty and provides performance on a level with, and in some instances exceeding, many closed-source counterparts.
Qwen2.5-72B-Instruct is a soft giant in the LLM world. Built by Alibaba’s DAMO Academy, this 72-billion parameter model anticipates, responds, translates, and adapts.
Indeed, the Qwen2.5 is a dutiful aide in its instruction-calibrated setup. It performs instructions flawlessly, whether that’s generating JSON, giving technical responses, or translating 29 languages.
In a word, it’s like having an attention-to-detail aide that gets your workflow.
What actually sets Qwen2.5-72B-Instruct apart is its architecture. The model can attain near-human sensitivity with logic and language.
That’s possible since it’s combined RoPE, SwiGLU, and RMSNorm with QKV bias attention. Otherwise, its 128K token window translates into large documents being available.
Key Features
- 72.7B parameters
- Structured output generation (JSON, YAML)
- 128K context window
- Proficient in 29 languages
- Advanced transformer architecture
| Pros | Cons |
| – Handles complex structured tasks with ease – Excellent in math, code, and multilingual tasks – Powerful instruction following | – Requires good hardware – Limited customization without deep LLM knowledge |
3. LLaMA 3.3-70B
Meta’s Llama 3.3 is the best open-source LLM, a conversationally optimized and primed for coding, writing, or just normal chat. If you’re after a general-purpose AI that doesn’t get in the way, Llama 3.3 is the obvious choice.
Supporting eight base languages and boasting a 128K context window, Llama 3.3 is multilingual and flexible.
You can throw just about anything at it, either a Python script or an essay in Spanish, and it will respond with courtesy.
This model also shines when it comes to performance efficiency.
It’s optimised for typical hardware, so powerful AI is accessible to more individuals. And with Meta’s documentation and engaged community, assistance is never out of reach.
Llama 3.3 is well-suited to create content, build chatbots, or build educational platforms.
Notably, it won’t always be great at very specialized tasks, but for well-rounded, reliable output, it will seldom get it wrong.
Key Features
- Supports English, French, German, Hindi, and more
- 128K context window
- Optimized for dialogue and multitasking
- Strong general knowledge and reasoning
- Wide community and ecosystem support
| Pros | Cons |
| – Excellent performance across various tasks – Resource-friendly – Large support community | – Not the best at ultra-specialized tasks – Limited creativity compared to larger models |
4. Mistral-Large-Instruct-2407
If you require a creative mastermind with a dash of science, Mistral-Large-Instruct-2407 is your model.
It’s a whopping 123 billion parameters, but with scale comes ability.
Additionally, it’s a master of both left-brain and right-brain tasks, blending code and creativity.
This resource is particularly well-suited to create something that requires structure and pizzazz. It can write a technical whitepaper or script out a dialogue-rich video.
Name it, and there’s a good chance it can do it with factual accuracy and stylistic flair.
Key Features
- 123B parameters
- 131K context tokens
- Native function calling
- Output structured formats like JSON
- Low hallucination rate
| Pros | Cons |
| – Exceptional at factual and creative content – Superior long-context reasoning – Ideal for enterprise and agentic AI use | – High resource requirements – Dense architecture limits scalability |
5. Phi-4
Microsoft’s Phi-4 is a small model that punches far above its weight class. It’s well-trained and tuned so as to deal with code, reasoning, and writing with surprising finesse.
The greatest strength of Microsoft’s Phi-4 is efficiency. Ideally, it doesn’t require costly GPUs or cloud credits since it operates on edge devices and laptops.
As a fact, Microsoft’s Phi-4 is perfect for developers, students, or small startups that require decent AI without the excess baggage.
Even though Microsoft’s Phi-4 is small in size, it never settles for less. Moreover, it excels in coding operations, logical issues, and lengthy content.
Since it consumes less power and memory, it is eco-friendly and easier to deploy.
Ultimately, the Phi-4 is your best bet if you need a fast, intelligent model that simply works.
It’s not the best with large data or numerous languages, but it is a light tool for daily use.
Key Features
- Compact size, high efficiency
- Optimized for edge and mobile devices
- Excels in coding and reasoning
- Runs with minimal GPU/CPU resources
- Competitive performance-to-size ratio
| Pros | Cons |
| – Lightweight and deployable almost anywhere – Strong performance in reasoning tasks – Great for edge computing | – Limited in multilingual and long-context use – Less powerful for creative writing |
6. Gemma 2-9B-IT
Google’s Gemma 2-9B-IT is trim, intelligent, and amazingly nimble. It’s the version you summon when you require quick solutions, elegant code, and solid output.
In spite of its 9 billion parameters, it performs like a larger model. Instruction-tuned and trained on quality data, Gemma 2-9B-IT is responsive to prompts.
It takes programming tasks, technical questions, and casual conversation in stride.
If you’re creating apps, scripting, or instructing computers to follow orders, Gemma 2-9B-IT performs.
It’s compact and powerful enough for local use to compete with the giants.
Key Features
- 9B parameters
- Instruction-tuned and optimized for developers
- Supports function calling and structured output
- Built-in safety guardrails
- Works on consumer GPUs
| Pros | Cons |
| – Lightweight and easy to deploy – Excellent for code and function tasks – Good safety features out of the box | – Limited long-context memory – Not ideal for deep creative writing |
7. Vicuna-13B v1.5
Vicuna-13B v1.5 is similar to speaking to someone who listens. Based on LLaMA 2 and extended through fine-tuning via ShareGPT-style conversation, this model is conversational in nature.
They are warm, constructive, and rather human-like responses. It comprehends tone, humor, and nuance better than other models of its size.
No matter if you’re creating a chatbot or composing interactive fiction, Vicuna introduces personality.
Key Features
- 13B parameters
- Finetuned on conversational data
- Excellent instruction following
- Natural, emotionally aware responses
- Based on LLaMA 2 foundation
| Pros | Cons |
| – Great for dialogue and chatbots – Easy to fine-tune or extend – Lightweight but expressive | – Not optimized for coding or math – Limited long-document reasoning |
8. BLOOMZ-7B1
BLOOMZ-7B1 is your gateway to worldwide communication.
Constructed by BigScience, this multilingual model reads and writes in more than 40 languages fluently.
Undoubtedly, BLOOMZ excels where most models fail: under-resourced languages, code-mixed text, and non-Western syntax.
It is also impressively good at summarization and translation, particularly for niche language pairs.
In that case, try BLOOMZ if you work internationally, have a multilingual website, or just prefer inclusive AI.
It is not necessarily the fastest, but it’s one of the most linguistically sensitive.
Key Features:
- 7.1B parameters
- Supports 40+ languages
- Instruction-tuned (BLOOMZ variant)
- Focus on diversity and linguistic coverage
- Open and research-oriented licensing
| Pros | Cons |
| – Exceptional multilingual performance – Ideal for translation and global NLP tasks – Open weights and datasets | – Slightly slower than newer models – Limited depth in English technical content |
Conclusion
If you’re a data scientist or developer looking for the best open-source LLM, Qwen2.5-72B-Instruct is the perfect deal.
Like the DeepSeek R1, it offers unprecedented reasoning capability and structure-aware generation.
Additionally, if you are dealing with restricted hardware, Gemma-2-9B-it, Phi-4, and Vicuna-13B provide lean but competent options.
While models such as the Command R+ and Falcon 2-11B compromise on size and speed, they are thus more ideal for practical uses.
And lastly, the open-source LLM ecosystem is no longer a cost-saving option, but it’s a leading choice powering innovation.
Whether it’s building next-generation applications, AI research, or custom assistants, these models keep you at the forefront.
Also Read:
